方便科研學術助手數據分析
在智慧圖書館中,用戶行為分析是AI應用的重要領域。通過分析用戶的搜索歷史、閱讀習慣和點擊模式等,智慧圖書館能夠深入了解用戶的興趣和需求,從而優化個性化閱讀推薦系統,提高推薦準確性和用戶滿意度。由于用戶的需求和興趣是動態變化的,定期進行用戶行為分析有助于智慧圖書館及時捕捉這些變化,并調整資源和服務策略。例如,當某一類圖書或資源的訪問量***增加時,智慧圖書館可以及時增加該類資源的購買量,以滿足用戶的需求;反之,當某一話題或領域的訪問量下降時,智慧圖書館可以調整資源配置,避免資源浪費。此外,用戶行為分析還能優化智慧圖書館的網站和用戶界面設計。通過分析用戶在網站上的訪問模式和交互行為,智慧圖書館可以識別出用戶體驗中的痛點和改進機會。例如,如果發現用戶在使用搜索功能時放棄率較高,可能意味著搜索功能需要優化,以提供更相關的搜索結果或更友好的用戶界面。通過對用戶行為的細致分析,智慧圖書館不僅可以精確滿足用戶當前的需求,還可以預見未來的變化,確保服務的持續有效性和相關性[3]。閱讀推薦服務是智 慧圖書館的服務之一,在海量信息中推送滿足用 戶需求的閱讀資源。方便科研學術助手數據分析

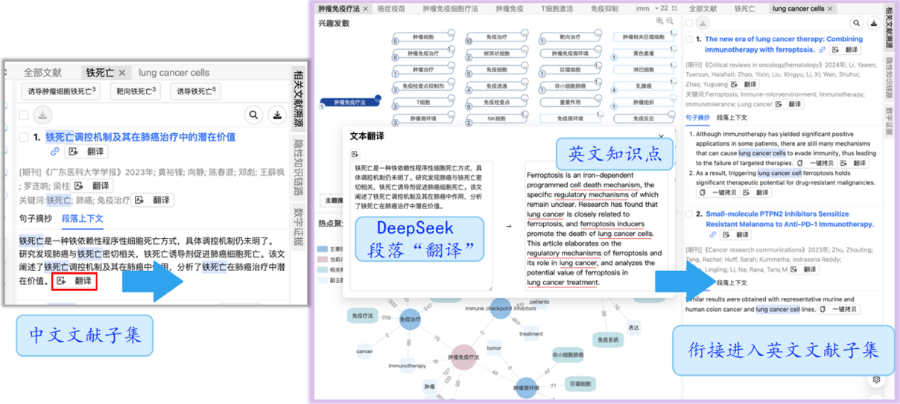
AI在智慧圖書館中的應用主要體現在信息檢索和文本分析兩大領域,能***提升智慧圖書館的工作效率和用戶體驗。在信息檢索領域以智能搜索引擎為例,數據顯示,用戶在使用這些工具時,搜索關鍵詞的使用率減少了20%以上。這是因為智能搜索引擎能夠更準確地理解用戶的查詢意圖,并提供相關的搜索結果。在文本分析領域,AI能夠處理和分析海量文本數據,從中提取出有價值的信息。這對智慧圖書館尤為重要,因為全球存在數十億份電子文獻需要高效管理。利用AI,智慧圖書館可以自動化完成文獻分類、關鍵詞提取以及信息摘要生成,從而提升數字文獻的管理效率,優化資源整理流程。采用AI,智慧圖書館可實現文獻分類、關鍵詞提取以及信息摘要自動生成等功能,從而極大提升了數字文獻管理效率。采用自然語言處理(NLP)與機器學習算法,智慧圖書館能自動識別、整理大量文獻資源,精細為每篇文獻分派類別標簽,并提取出**關鍵詞及主題要點,不僅削減了人工整理的時間成本,還減少了人為方面的錯誤,提升了文獻分類的精細度;智慧圖書館可以生成簡要的文獻摘要,使用戶得以迅速了解每篇文獻的**要義,便于高效、迅速地從海量資源中篩選出滿足自己需求的文獻。咨詢科研學術助手概況情景感知技術作為泛在 計算的關鍵部分,是圖書館構建泛在智慧服務的重 要技術要素。
除了聊天機器人外,AI技術還廣泛應用于智慧圖書館的互動式閱讀體驗。通過集成語音識別、面部識別等先進技術,智慧圖書館能夠打造一個充滿活力的數字化閱讀社區。在這個社區中,讀者可以在虛擬空間中與系統進行互動,參與各種閱讀活動。例如,智慧圖書館可以定期舉辦線上讀書會、知識講座等活動,利用AI技術進行實時互動和討論。這種互動方式不僅可以增強讀者的參與感和歸屬感,還能促進讀者之間的交流和分享,推動閱讀文化的傳播和發展。此外,AI技術還可以用于智慧圖書館的座位管理和圖書追蹤等場景。通過智能座位管理系統,讀者可以實時查看圖書館的座位使用情況,選擇**合適的座位進行閱讀。而圖書追蹤系統則能夠實時跟蹤圖書的位置和狀態,為讀者提供更加便捷的找書服務。智能化的應用場景不僅能提高讀者的閱讀便利性,還能進一步提升智慧圖書館的服務質量和水平。
智慧閱讀是AI技術賦能閱讀的初步探索,其潛力遠未被充分挖掘。隨著生成式人工智能、增強現實、腦機接口、生命科學等前端技術的不斷突破和落地應用,人類即將迎來超級閱讀時代。作為智慧閱讀的高級階段,超級閱讀并非智慧閱讀的簡單延續,而是通過更深層次的技術賦能,帶給讀者多模態交互增強的閱讀體驗,幫助讀者突破傳統的閱讀方式限制,提高閱讀效率,優化知識管理模式,甚至將閱讀過程與知識輸出、社會互動深度融合。技術創新主導的超級閱讀活動,其基本架構包括感知層、交互層和認知層,呈現全新的特征。為用戶提供信息資源服務、深加工的知識服務,特色文化空間、智能共享空間。
智慧圖書館應確保只有授權的員工才能訪問敏感的用戶數據,并且訪問權應根據員工的職責進行嚴格限定。每次訪問都應有記錄,以便進行安全審計和監控。再次,安全審計是另一項重要措施。定期的安全審計可以幫助圖書館發現潛在的安全漏洞和不當的數據處理活動。同時,審計結果可以用于加強數據保護和修正已識別的弱點。***,智慧圖書館應公開其數據保護政策,明確告知用戶其個人數據如何被收集、使用和保護,并確保其數據處理和存儲實踐符合當地和國際的隱私法規。合理的隱私政策和用戶協議應該清楚地展示給用戶,并且在用戶注冊過程中獲取用戶明確的同意,有助于建立用戶信任,提高其對個性化推薦服務的接受度。在用戶中建立品牌形 象,可以促進用戶對閱讀推廣品牌認知和提升用戶 的閱讀體驗。一站式科研學術助手簡介
做好館員新型專業/服務能力體系 的重構和布局至關重要。方便科研學術助手數據分析
個性化閱讀推薦系統的設計始于高效且精確的數據采集、處理與分析。在智慧圖書館中,用戶每天進行搜索、閱讀和下載等互動行為均會產生大量數據。以大型智慧圖書館為例,其每月會新增數千份電子書和期刊,且數百萬用戶的日常活動會生成海量數據記錄,包括搜索查詢、點擊和下載等行為數據。這些數據是設計個性化閱讀推薦系統的基礎,需要收集和處理,以便后續進行分析和應用。數據采集必須***覆蓋用戶數據,包括用戶的注冊信息、借閱記錄、閱讀習慣,以及用戶與智慧圖書館資源的交互方式等。依托上述數據,個性化閱讀推薦系統可掌握用戶的基本興趣和偏好,鑒別用戶潛在的興趣領域和行為模式,從而為推薦給予數據方面的支持。方便科研學術助手數據分析
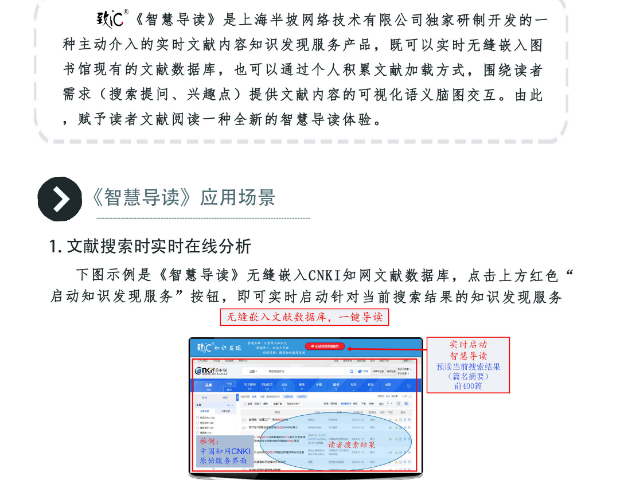
- 天津智慧導讀優勢 2025-12-09
- 智慧導讀聯系人 2025-12-09
- 哪些智慧導讀口碑推薦 2025-12-09
- 品牌智慧導讀采購 2025-12-09
- 四川智慧導讀排行榜 2025-12-09
- 哪個智慧導讀常見問題 2025-12-08
- 圖書館智慧導讀用戶體驗 2025-12-08
- 參考智慧導讀常見問題 2025-12-08
- 江蘇智慧導讀客服電話 2025-12-08
- 品質智慧導讀互惠互利 2025-12-08
- 工業園區推廣抖音運營常見問題 2025-12-09
- 廬江營銷團建服務策劃 2025-12-09
- 宜興方便人事外包概況 2025-12-09
- 甘肅哪些展覽服務 2025-12-09
- 坪山區招投標補貼申報時間 2025-12-09
- 泗陽智能化展覽服務報價表 2025-12-09
- 靜安區參考倉儲服務優勢 2025-12-09
- 南寧可靠文檔 2025-12-09
- 廣西自動化文檔整理 2025-12-09
- 深圳話劇票員工福利采購平臺定制方案 2025-12-09